If you want to train your data set, then at least you must know these 3 Layers.
Layers

Dense Layer
We called this “the most well-known type of the Layer”. You can use this layer if you want to adding more Layer because your model need to more memorize some values.
Too much Dense Layer will causing Overfitting training.
Too less Dense Layer will causing your training is far from the best result.
And usually we added Dense Layer at the end of sequence of layers for fitting the number of output to number of classes.
Convolution Layer
This layer for training image datasets.
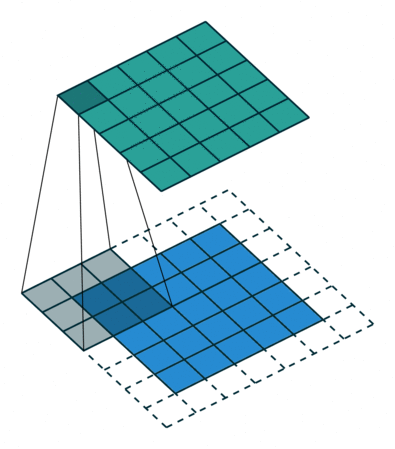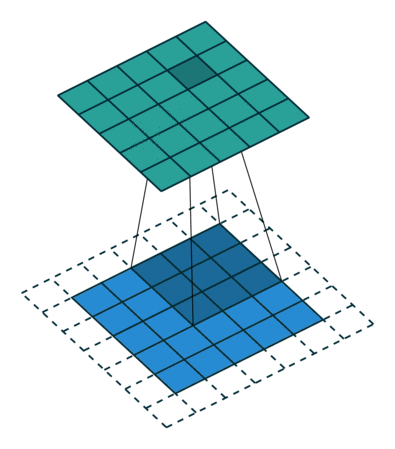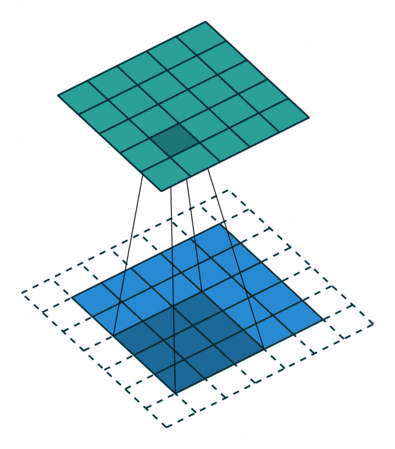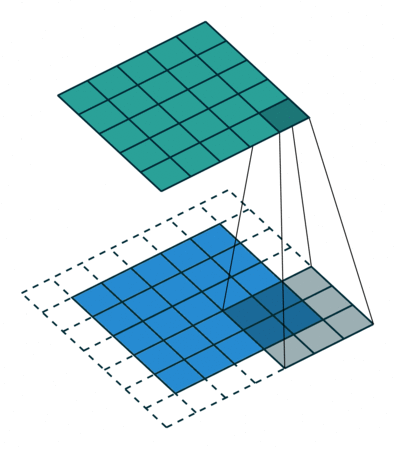
We can pass the dimension of window you need to capture the group of pixels. Lets say 3 by 3. Capture to create a feature (on that maybe the model found some symbol or pattern like circle or square or other things). Stride and capture until the end of pixel.
Flatten Layer
This can convert the output of Conv2D to DenseLayer. From 2D value to single value layer
And if you use this for input layer, then you don’t need to specify the input. Because the input will be flattened.
MaxPooling
For me it’s not a layer. This use with Convolution Layer. To pooling the max value from Convolution Layer.
After create Convolution layer we add this. This optional. Maxpooling will get the max value from features by the size of pooling pool_size.
Why we need Max Pooling?
Because max pooling can reduce the amount of pixels, so that can make training faster. Also max pooling can reduce the over fitting. Because only the max value will be stored, not the exact of all the value of pixel.
DropOut (additional layer)
For me Dropout is not a Layer. If your training result is overfitting, then you can use Dropout.
In some cases drop out very useful, since the behavior is different with just reduce neurons number or reduce layers number.
In random way Dropout remove some neurons as many as number given at parameter. Random per each epoch process. And will ignored in test or predict processing.
Don’t ever forget to add activation function every time you added a new layer
